Apache Spark vs Hadoop
Apache Spark vs Hadoop is an interesting comparison between two key technologies that are able to work with big data. One aspect for understanding a key difference of both relies in the fact that the speed of reading data from harddisk is much slower than reading from random access memory (RAM) for a CPU. In other words the CPU is doing the actual processing of the data and can quickly access the RAM for required data. But when the data only resides on harddisks reading the data is slow and needs to be performed via RAM and then in turn read into the CPU. All of this takes considerable time.
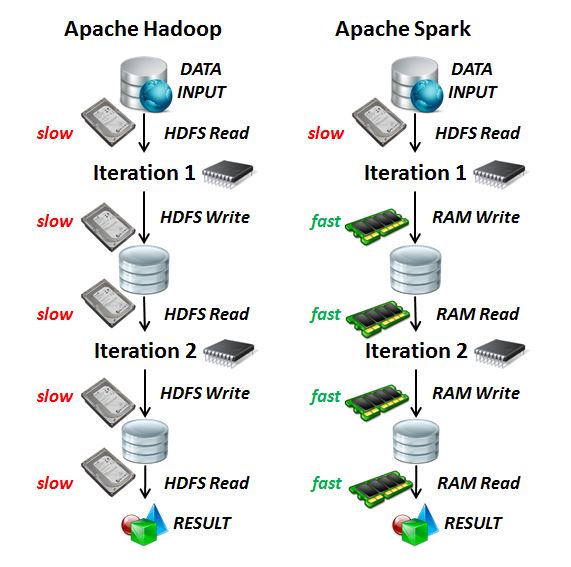
Apache Spark is optimized to use as much cache and RAM as possible while Hadoop is rather file oriented and as a consequence uses often the harddisk. Apache Spark however uses certain elements of Hadoop such as the underlying Hadoop Distributed File System (HDFS). One key difference between Apache Spark vs. Apache Hadoop is therefore that slow HDFS reads and writes are exchanged with fast RAM reads and writes in several iterations that might be part of a larger workflow. In this context a workflow is a sequence of processing tasks on data that leads to results via ‘iterations‘. Apache Spark requires therefore ‘big memory‘ systems in order to perform really well thus reaching to 100% better performance than Apache Hadoop. The following figure illustrates one difference of both technologies:
Apache Spark vs Hadoop details
We refer to the following video for getting more details about this subject:











