Cross Validation
Cross validation is a smart technique to perform model selection during the validation process. The model selection performs a decision about a specific machine learning model (e.g. artificial neural network, decision trees, suppor vector machine, etc.) or a specific parameter set for a choosen model (e.g. kernel parameter for a specific Support vector machine). These decisions about the model are directly related to the model complexity that in turn can be problematic due to the problem of ‘overfitting the data’. The two solution methods for avoiding overfitting are (1) regularization and (2) validation. In this contribution we focus on the (2) validation process while strongly encouraging end users to use also (1) regularization in practical problems. The main utility of the cross validation technique is model selection supporting a concrete decision to choose a machine learning model.
Problem of Splitting Data for Validation Set
In a practical problem a machine learning user received N samples of data in order to find some pattern in the data. This N samples then need to be seperated in a ‘training set’ and ‘testing set’. How exactly the data is seperated depends on the given problem at hand and on the availability of data. The training set is used for ‘training process’ while executing a machine learning algorithm. This results in a ‘trained machine learning system’. The testing set is then used with this system in a ‘testing process’ in order to check whether the trained system might work well for unseen data. The result of this process is the accuracy of the trained model system. In order to Keep the ‘testing set’ clean that refers to ‘unseen data’ any model decisions should be not taken part in the testing process. Instead another validation set is introduced that is used to perform model selection. The following figure illustrates the problem of using k samples for validation when splitting the dataset with N samples. This means we take samples away from the training process which in turn is a bad idea according to statistical learning theory: the more samples we have the better we generalize to unseen data.
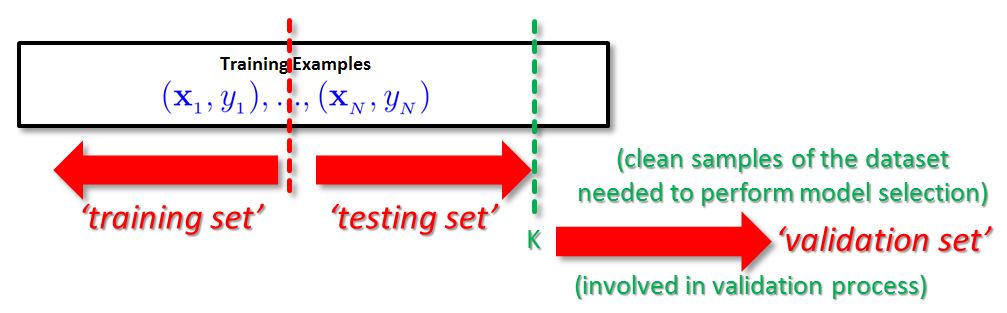
Cross Validation Approach
The validation set above provides elements of the dataset that have been not used in the training or testing process. It is a clean dataset required to reliably estimate the out-of-sample performance of a choosen machine learning model selection. This is a practical and very systematic process. Cross validation is a technique that provides a smart approach to avoid the problem of splitting the dataset introduced above. It enables the use of N dataset items for training and N Points for validation at the same time while keeping the dataset almost ‘clean’. Clean here refers to be unbiased of decisions performed so far. The key idea of cross validation is to repeat the number of trainings of different subsets. That means we train multiple times a machine learning model using leave-one-out or leave-more-out in the cross-validation process. The idea is to have N/K Training sessions on N – K data items that is referred to as k-folds. For example, 10-fold cross validation is mostly applied in practical problems by setting K = N/10 for real data. The Illustration below shows the general idea including the general ‘leave-out’ strategies.
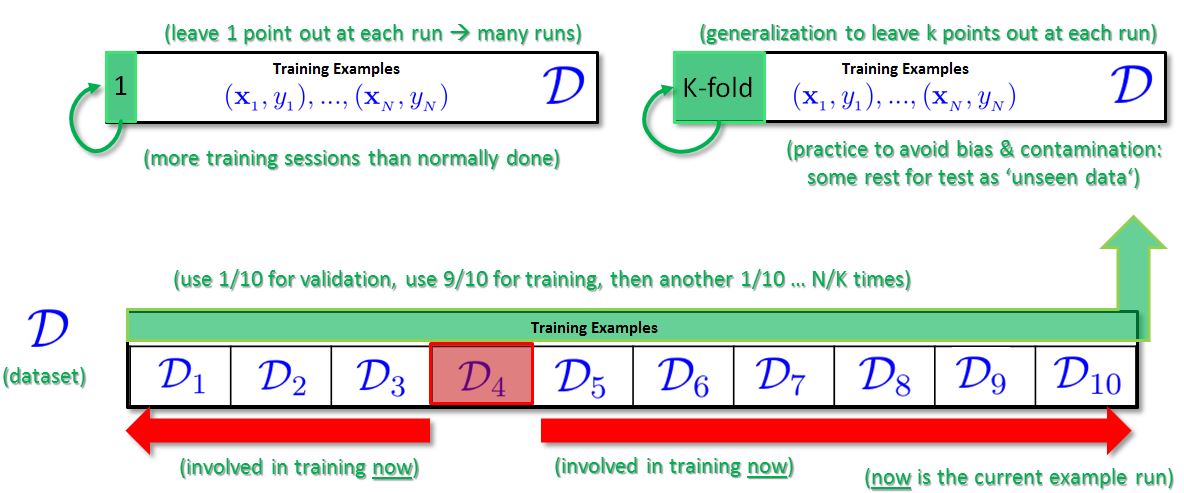
More information about cross validation
The following video illustrates the validation process in short including cross validation:
Follow us on Facebook:











