Machine Learning Methods
Machine learning methods can be roughly categorized in three different areas in order to analyse big data. The figure below shows an overview of all the three different areas. Those machine learning methods can be roughly categorized in classification, clustering, or regression augmented with various techniques for data exploration, selection, or reduction. In many real application use cases one tends to use also multiple of those methods. One example is to perform clustering in order to determine groups of data followed by subsequent classification methods that uses this group information. More details on the different methods is described below.









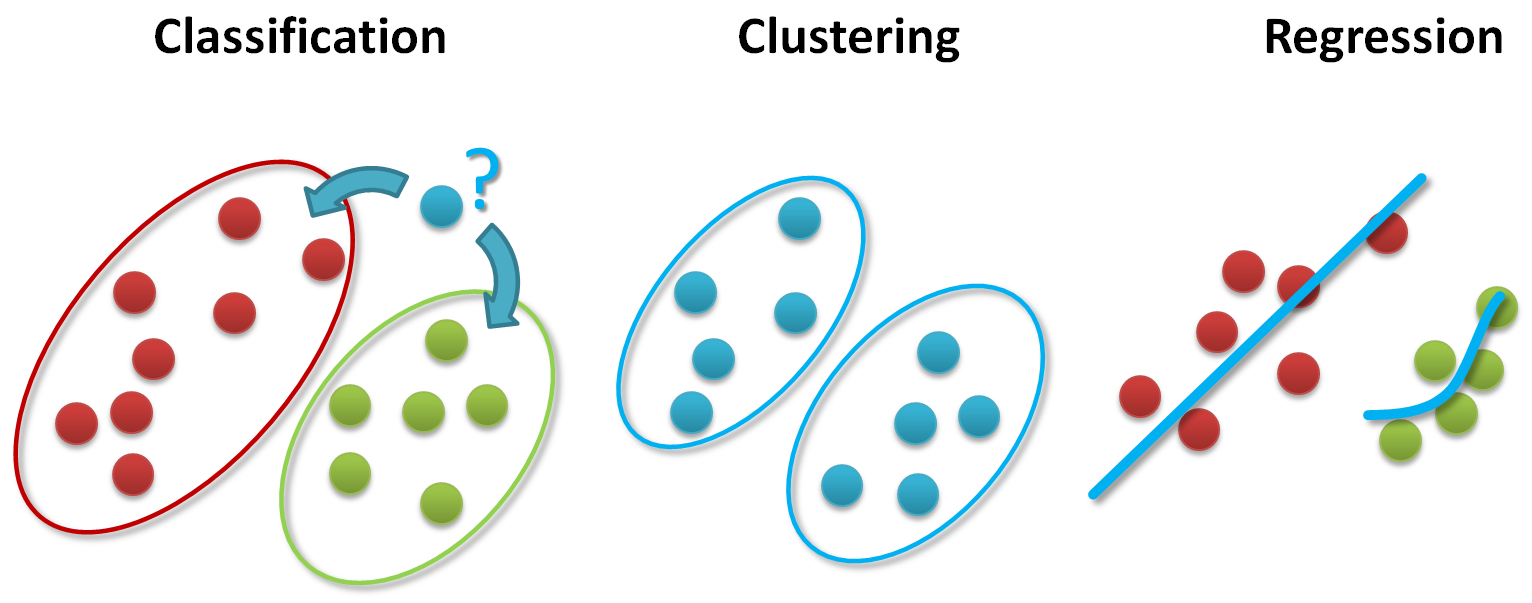
In classification distinct groups of data exist and new data elements should be classified into these existing groups. One example is to classify the type of a newly seen flower to one or another group of flowers depending on the properties of the newly seen flower. In clustering no groups of data exist initially but one creates groups from the data close to each other. One example is to use similarity measures like Euclidean distance also known as the ‘ruler distance’ to identify points close to each other and to assign them to the same groups. In regression methods the idea is to identify a line with a certain slope that is able to describe the data. In this context one example is often to understand the relationship between how much advertising money in needed for marketing in order to increase the sales of products to some certain level.
Machine Learning Methods Details
Please have a look at the following video:











