Data Classification
Data classification is one of the three key machine learning methods in order to make use of big data. One simple application example is shown below illustrating the classification of a flower type based on known flower types. In this example, the groups of flowers known as Iris exist as several classes such as ‘Iris Setosa’ and ‘Iris Virginica’. A new flower that looks similar should be classified into those existing groups based on its data features or data properties. This process is known as data classification.









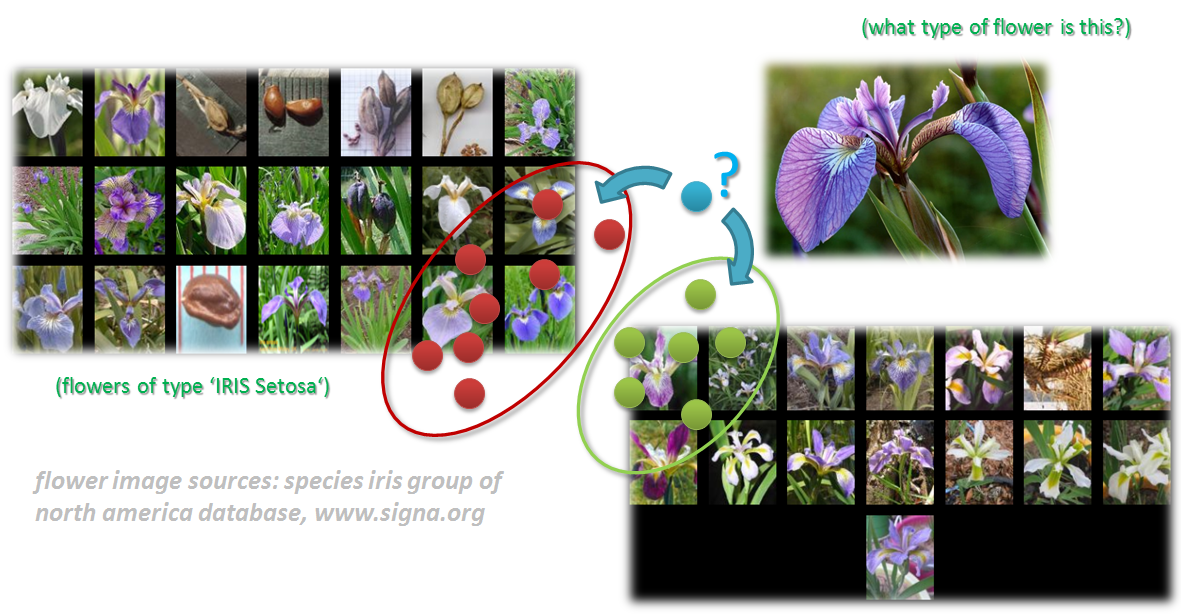
The particular machine learning problem in this two class or binary data classification is a prediction task. The goal is to determine or to classify a new Iris flower sample as the type ‘Setosa’, ‘Viginica’. In order to classify the flowers it is important to use attribute data or feature data about the new Iris flower sample. Examples for the attributes or features are sepal length in cm, sepal width in cm, petal length in cm, and petal width in cm. Experts for plants might be able to do this but generally machine learning is helpful here to perform this task as well and thus to automate this data classification process.
Data Classification Details
We recommend to watch the following video:











