ReLU Neural Network
ReLU Neural Network is a well known phrase that stands for the Rectified Linear Unit (ReLU) activation function used more recently during the training of neural networks and deep learning networks used with big data. Traditional activation functions have been tanh or the sigmoid. The ReLU function is defined as f(x) = max(0, x). The particular interesting property of this function is that its outputs are 0 for negative values of x or x itself in case it is positive. Experts refer to this as a ‘ramp function’. That is very convenient for many algorithms and machine learning models such as within a Convolutional Neural Network. The following statistical computing with R example shows the values of a ReLU whereby x is in the range of -5 and 5.
> f = function(x){pmax(0,x)}
> x = -5:5
> y = f(x)
> dataset = data.frame(x,y)
> dataset
Output:
x y
1 -5 0
2 -4 0
3 -3 0
4 -2 0
5 -1 0
6 0 0
7 1 1
8 2 2
9 3 3
10 4 4
11 5 5
As the dataset printout above reveals all values of y are 0 for negative values of x while x itself is returned for positive values of x. A corresponding function plot is shown below in the range of x between -5 and 5 from this dataset. For more details on how to draw such a simple function plot we refer to our article on plot function. The first line of the R code above implements the ReLU function. Note that the max() function of R would only provide a 5 in this case for all values as it returns the maximum of a whole vector. The used function pmax() instead is a parallel maximum function. This means the first element of the result is the maximum of the first element of vector x or 0, the second element of the result is the maximum of the second element of vector x or 0 and so on. The pmax() function is directly available in R and we do not load a specific library here.
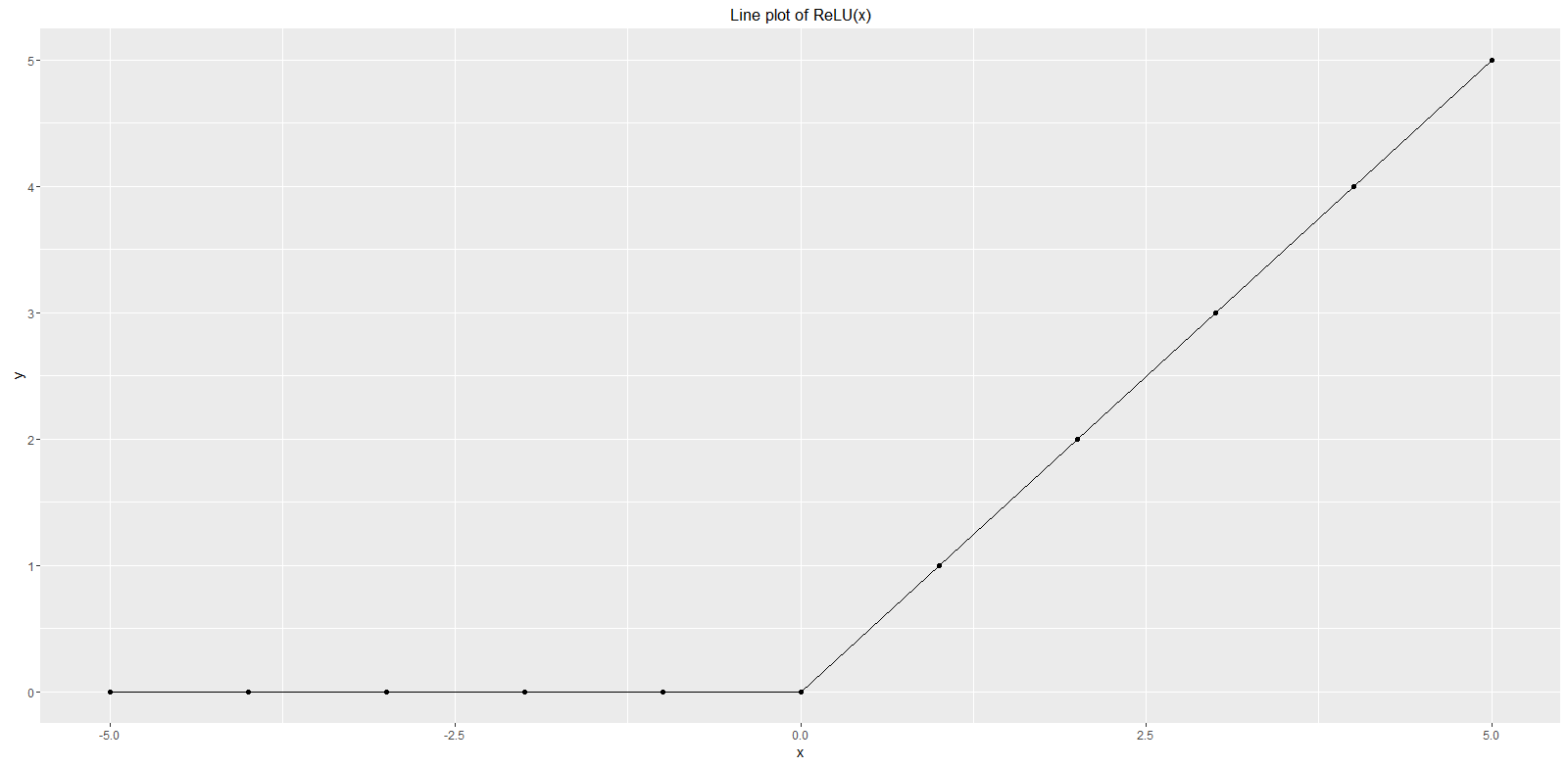
Please refer to our article on tanh for another often used activation function.
ReLU Neural Network Details
In order to find out more about this topic we recommend to check the following video:











