tanh
Tanh stands for hyperbolic tangent function and it is often used as a non-linear activation function in machine learning algorithms when working with big data. The particular interesting property of this function is that its outputs only range from -1 to 1. Experts refer to this as a ‘squashing function’ meaning that an input x is squashed between -1 and 1 with the tanh activation function. That is very convenient for many algorithms and machine learning models such as within a neural network. One particular example where tanh is used with this property is the Long Short Term Memory. The following statistical computing with R example shows the values of tanh(x) whereby x is in the range of -5 and 5 and that will be ‘squashed’ between -1 and +1.
> f = function(x){tanh(x)}
> x = -5:5
> y = f(x)
> dataset = data.frame(x,y)
> dataset
Output:
x y
1 -5 -0.9999092
2 -4 -0.9993293
3 -3 -0.9950548
4 -2 -0.9640276
5 -1 -0.7615942
6 0 0.0000000
7 1 0.7615942
8 2 0.9640276
9 3 0.9950548
10 4 0.9993293
11 5 0.9999092
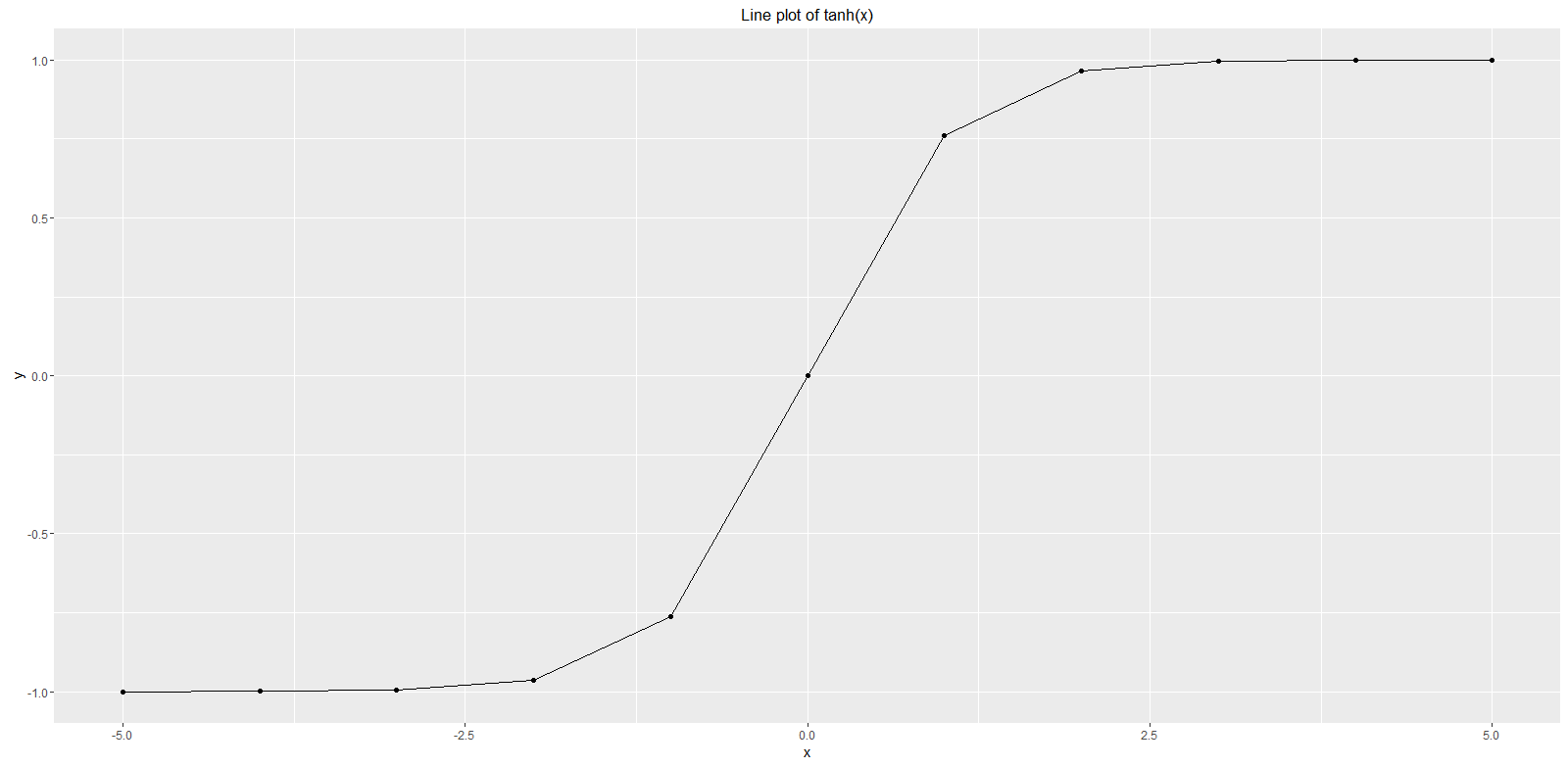
As the dataset printout above reveals all values of y are still between -1 and +1 with increasing and decreasing values for x. A corresponding function plot is shown below in the range of x between -5 and 5 from this dataset. For more details on how to draw such a simple function plot we refer to our article on plot function. The graph shows that tanh(x) is continuous on its domain, differentiable, bounded, and symmetric since tanh(-x) = -tanh(x). Furthermore the graph reveals that there are no local extrema and that there is a zero point exactly at x = 0 that in turn is also a point of inflection. One can observe that tanh(x) is also sigmoidal with the so-called ‘s- shape’. But while a standard sigmoid function has only output between 0 and +1 the tanh function enables output values between -1 and +1 that in turn is often better for activation functions in machine learning algorithms. One of the reasons is that negative inputs will be mapped strongly negative and the zero inputs will be mapped near zero.
Please refer to our article on ReLU Neural Network for another often used activation function today.
Tanh Details
The following video provides more pieces of information about this topic:











